
Yoshinaga Laboratory
Research on Distributed Parallel Computing
A distributed parallel computing system involves multiple computers connected and coordinated in a network, and has much greater processing power than a single computer. However, such a computing system requires consideration of issues such as how to exchange information, how to coordinate these exchanges of information, and how to deal with a system failure. Even with a number of the world’s fastest computers connected to the network, distributed parallel computing can be implemented effectively only by fully utilizing the capabilities of the individual computers. It is therefore important for applications to exploit the computing environment to the fullest.
Optical Interconnection Technologies
One of the major issues in the development of supercomputers of the next generation and beyond is to develop hardware that offers both low power consumption and high performance. On-chip optical network technology and chip-to-chip optical interconnection technology are potential solutions to this issue that are attracting attention as network technologies for supercomputers.
Communication protocols compatible with optical interconnection include circuit-switching and similar protocols. There is a strong need for a new communication system that differs from the packet communication system used for conventional electrical networks. Our laboratory is researching new communication protocols suitable for optical interconnection, as well as high-performance, high-reliability network configurations and a high-speed communication library.
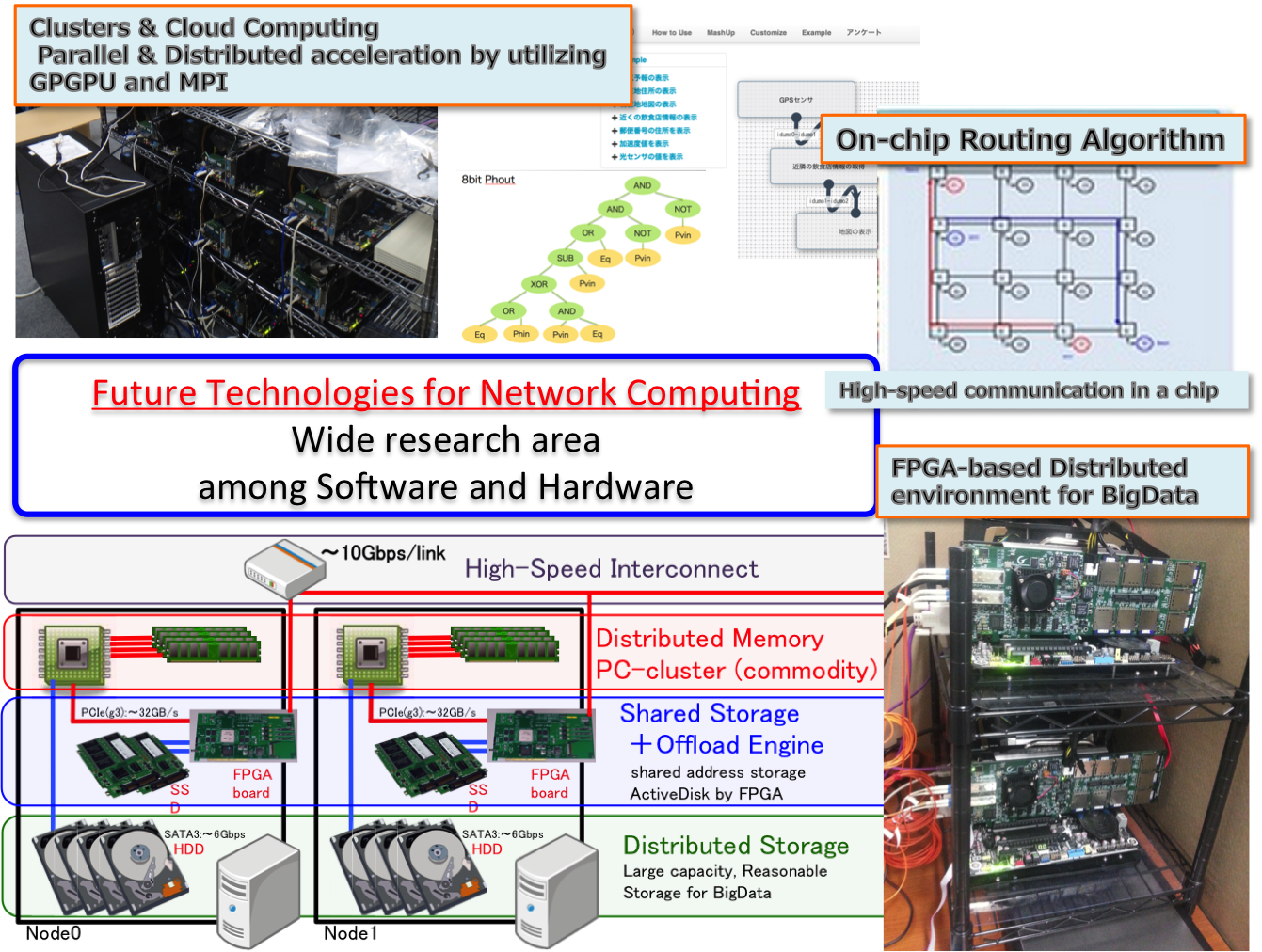
A Foundation for Dedicated Hardware-Assisted Big Data Analysis
As a result of the advances in both Internet and sensor technologies, enormous amounts of data on society and people’s lives are being stored. Extensive attempts have been made to discover new sources of value through analysis of big data. However, there are many technical issues to be addressed to achieve high computing speed with efficient use of energy. In particular, the time required for reading, sorting, and compiling data accounts for a large portion of total computation time, and is the cause of a significant decrease in computational efficiency. Our laboratory is developing hardware to closely connect storage to an optical network via field-programmable gate array (FPGA) devices.
We are also researching a compact, high-performance computing system for big data analysis in which communication processing is performed, a portion of the computing is off-loaded, and data access is integrated with computing.
Cloud Computing as a Computing Resource
Cloud computing using a powerful computing system via the Internet contributes to reductions in running costs and improved convenience. With this as a background, a mechanism is required in which a number of virtual machines in operation share powerful physical devices to achieve both high performance and flexibility.
Our laboratory is researching a cloud computing system in which a resource pool is created in the cloud to allow the functions and capabilities of virtual machines to be used as needed. We are working to improve the energy-efficiency performance of such a system using a configuration in which virtual machines with a minimal configuration can optimally use abundant computing resources.
Development of an Accelerator-Compatible Scientific Computational Algorithm
In recent accelerators with a large number of CPUs, such as GPU and Xeon Phi, a number of threads perform effective single instruction multiple data (SIMD) operations to achieve high-speed computing. However, slightly complex operations, such as conditional branching, tend to cause significant performance degradation. Research to develop algorithms suitable for implementation in accelerators is therefore important. Our laboratory is working on such accelerator algorithms, with a focus on the Smith-Waterman algorithm to find similarities in biological information such as genes and amino acids.
Programming-Free Mashup Framework
With the appearance of various Internet services in recent years accompanying the widespread use of smartphones and tablets, mobile device users are employing “mashups” to create their own applications by combining a number of services. The issue in mashups is to develop a framework that is easy to use and requires no programming.
Our laboratory is developing the IDUMO mashup framework to allow the development of applications by arranging and interconnecting functional blocks through a graphical interface.
The Advantage of Our Approach
Research on a Wide Range of Topics from Architectures to Applications
A key characteristic of our laboratory activities is that we perform research on architectures, system software programs, and applications from a multidisciplinary and multifaceted perspective to maximize the performance of distributed parallel computing systems.
Designing a distributed parallel computing system requires deep knowledge of computers and network architectures. The most important feature of distributed parallel computing is the fast and reliable execution of applications. An extensive understanding of the behavior and characteristics of applications is required to achieve this objective. Our laboratory is researching all layers of distributed parallel computing, from architectures to applications, and has proposed a truly practical distributed parallel computing system. This is a significant advantage in presenting effective uses of distributed parallel computing.
Future Activities
Taking the Next Step Forward from Basic Research to Applied Research
In 2012, we launched a research project to integrate computation and achieve higher computing density, including a distributed processing framework with dedicated hardware that can use existing software assets and an algorithm for the effective use of all of the cores of many-core processors. We are researching methods for providing applications with low power consumption, high performance, and high functionality that are not currently available, by appropriately distributing tasks to be processed and performing efficient computation with the appropriate computing resources.
We will continue our research on the security of P2P networks, whose importance is expected to increase even further, and on high-speed processing with a dedicated FPGA-based architecture. We will also further improve the performance and reliability of computing systems using the results of basic research accumulated over the years, and will develop applications from this basic research. Through these efforts, we intend to make ongoing contributions to the development and maturation of a new information society through research on computing systems with low environmental impact and low running costs, which will provide maximum benefits with the minimum use of energy.
Other Information
Research topics in our laboratory are also introduced by
The University of Electro-Communications Center for Industrial and Govermental Relations OPAL-RING.
Research Topics
- Interconnection Networks
- Network Computing (Japanese)
- Reconfigurable Computing Sustems, FPGA (Japanese)
- How to join Yoshinaga Lab. (Japanese)
Class Information
Contacts
The University of Electro-Communications
Graduate School of Informatics and Engineering
Department of Computer and Network Engineering
Laboratory for Network Computing
1-5-1,Chofugaoka , Chofu, Tokyo, JAPAN, 182-8585
tel:+81-42-443-5636
Email:yoshinaga_at_uec.ac.jp
