
吉永研 配属希望の方へ
このページに関する質問・相談は,お気軽に下記までお問い合わせください.
- 吉永 努 教授 (yoshinaga _at_ uec.ac.jp)
- 研究室公開 https://comp.lab.uec.ac.jp/opencampus2023
- 22年度の公開 https://comp.lab.uec.ac.jp/opencampus2022
私達と一緒に研究しませんか?
吉永研究室は,大学院情報理工学研究科 情報ネットワークシステム学専攻 コンピュータサイエンスプログラムに属しています.ネットワークが大好き,ケータイが手放せない,スーパーコンピュータが好き,パソコンに囲まれて暮らしたい, 人に使ってもらえる研究成果を出したい,先進的な研究をしたい,…そんな人は,ぜひ一緒に研究しましょう! そして,研究成果は国内外の学会や論文誌に,どんどん発表しましょう.企業や他大学,研究所との共同研究も 多数行なっています.積極的に研究して大学生活を充実させたい方,ひとつの研究室に留まらず,外部の研究者と交流を持ちたい方,大歓迎です.

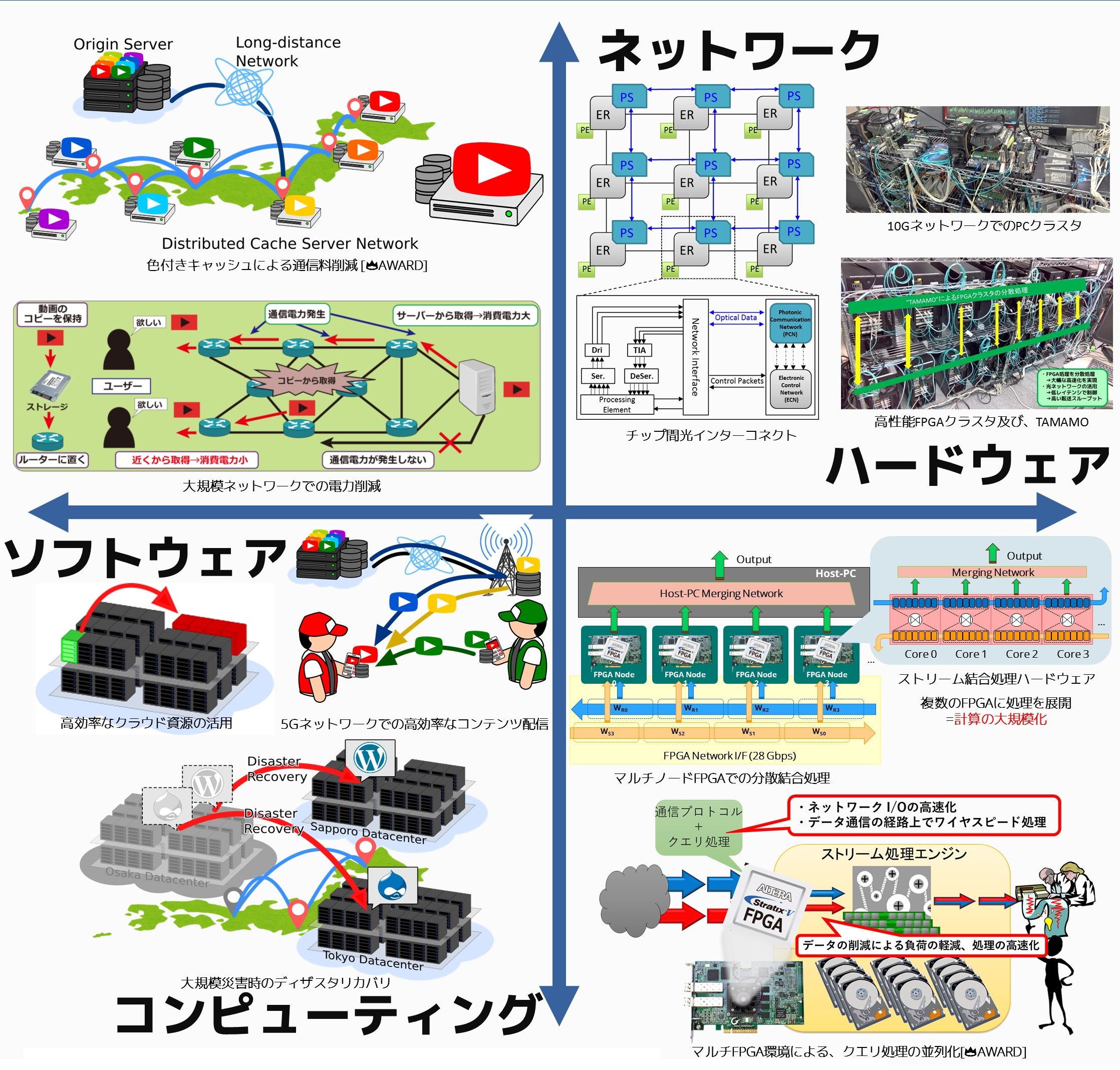
ハードウエアからサービスまで,ネットワークを広く扱っています
吉永研究室では,ネットワークとコンピュータの融合分野を, ハードウエアからソフトウエアまで,幅広く扱っています.
教員の専門分野のキーワードは,以下の通りです.
吉永 努 教授
計算機システム,計算機ネットワーク,ルーティング・アルゴリズム,クラスタ・コンピューティング,並列分散処理,ネットワーク・コンピューティング,セキュリティ,GPGPU,FPGA

専用ハードウェアによる計算アクセラレーション
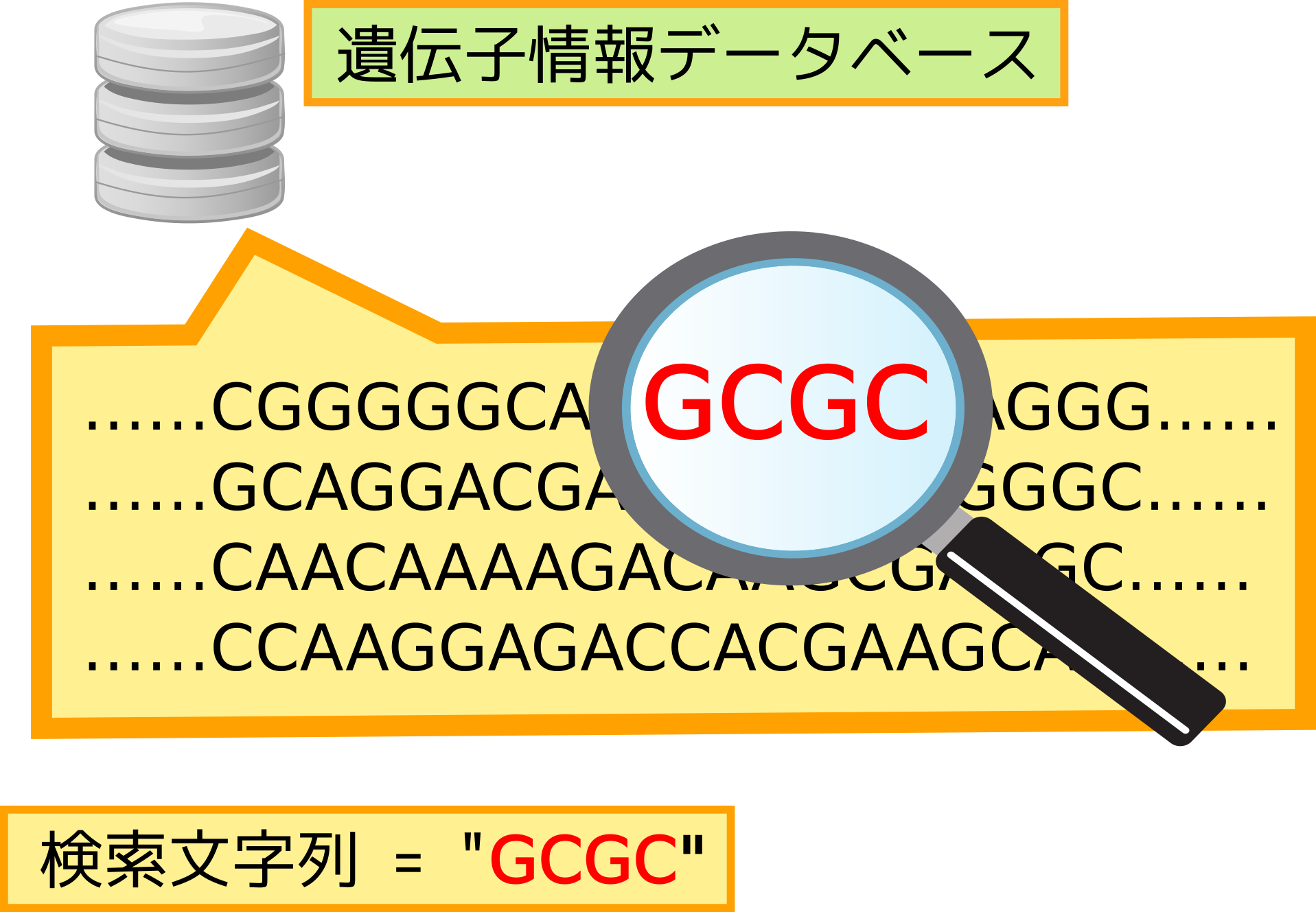
配列類似性検索の高速化
遺伝子配列などのテラバイト規模のデータに対して,FPGAを用いて高速な走査・マッチングを実現します.
ビッグデータ処理の高速化
大量のデータを多角的に分析して知見を得るビッグデータ処理が一般化し、広く使われています。我々は、データの生成から処理・解析まで、全てにおいてビッグデータはネットワークと密接に繋がっている事に着目しました。例えば金融情報やセンサデータはネットワークを介して流入し、蓄積されたデータは処理用のクラスタネットワークで共有され分析されます。我々は、ネットワーク端子を持つFPGAボードを利用して、二種類のビッグデータ解析の高速化に取り組んでいます。

大量データの高速な検索
ビッグデータ処理の一つは、大量のデータに対する迅速な解析です。我々は、FPGAを利用してデータの読出し・整理・検索・照合・抽出の高速化に取り組んでいます。
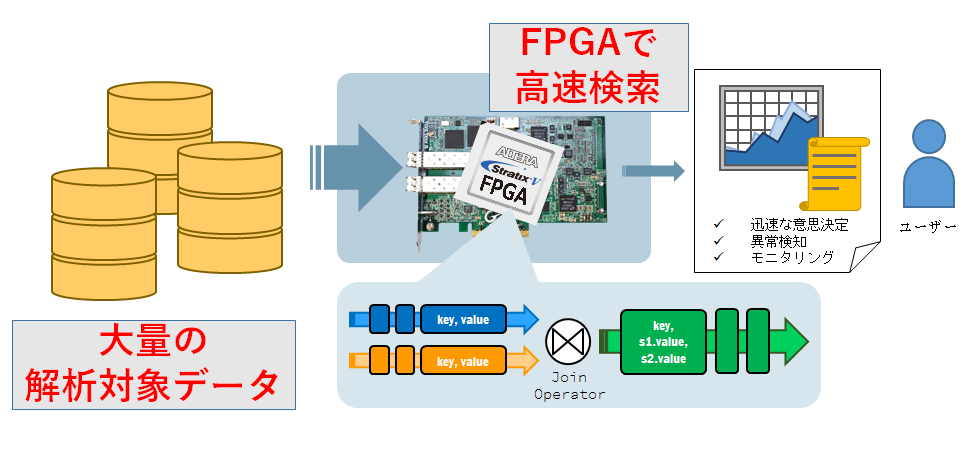
ストリームデータ解析の高速化
もう一つのビッグデータ処理は、入力され続けるデータの高スループット・低レイテンシな処理です。短時間に大量のデータが生成されると、データ処理エンジンに許容量を超えたデータが流入してしまい、正確な解析ができません。我々は、入力され続けるデータの処理をFPGAにオフロードして、大量のストリームデータに対する高速・低レイテンシな処理に取り組んでいます。

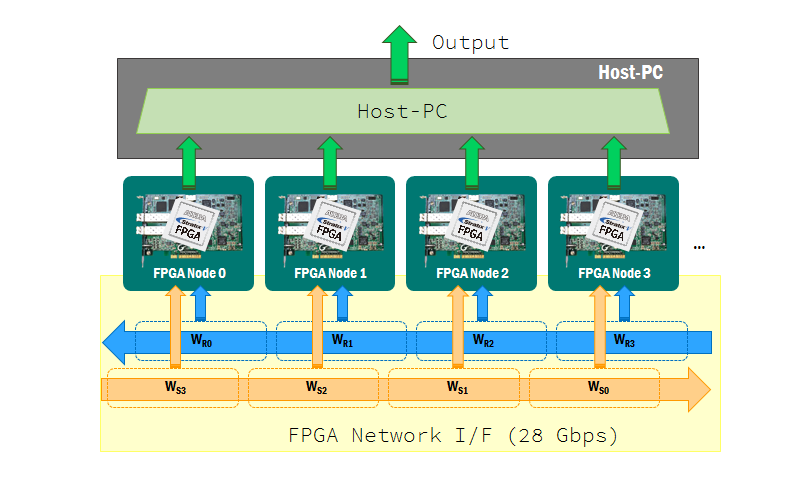
複数FPGA連携によるスケーラビリティの向上
更に,上記二種類のビッグデータ処理のスケーラビリティ向上に取り組んでいます.一枚のFPGAボードが扱えるデータ量は,ボードのリソース量に制限されるので,スケーラビリティの面で問題があります.そこで,我々は複数枚のFPGAボードに処理を分散して実行する基盤を開発し、上記の二種類のビッグデータ処理に対する高いスケーラビリティの実現に向けて取り組んでいます。
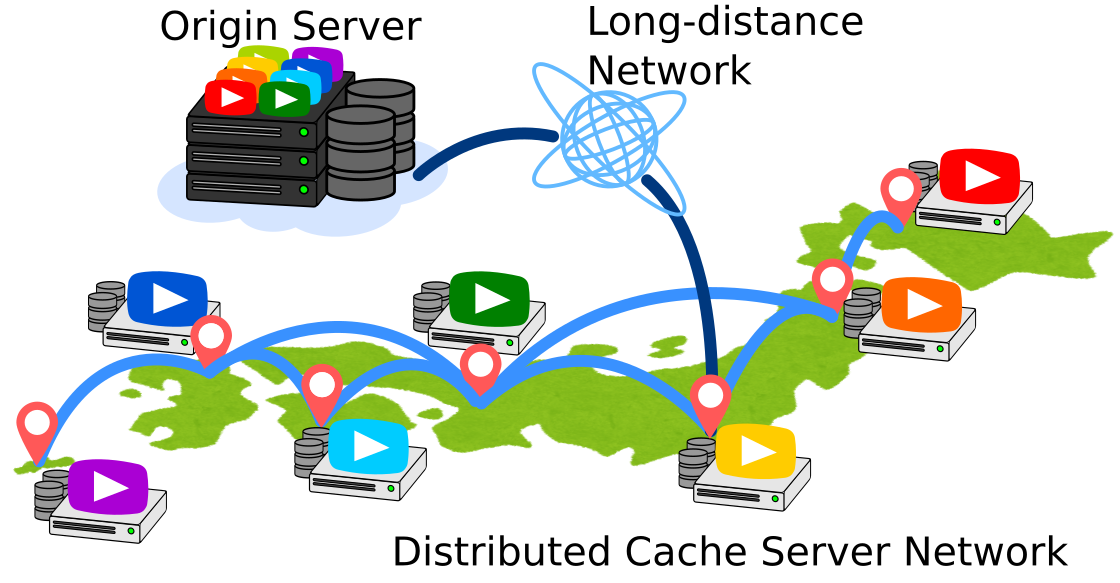
分散協調キャッシュによるインターネット通信量の削減
YouTubeやNetflix,Huluなど,いつでも好きな動画を見られる動画配信サービスの普及に伴い,インターネット通信量は急激に増大し,その約8割は動画で占められています.増大する通信量はネットワークに大きな負荷をかけるため,ネットワークを通過する動画データを途中のサーバにコピーを保存し,2回目以降は保存した動画データを再利用するキャッシュサーバが活用されています.我々は,複数のキャッシュサーバを協調させて実効キャッシュ容量を拡大し,効率よく利用することで,さらなる通信量の削減と,それに伴う省エネルギーなネットワークの実現に取り組んでいます.
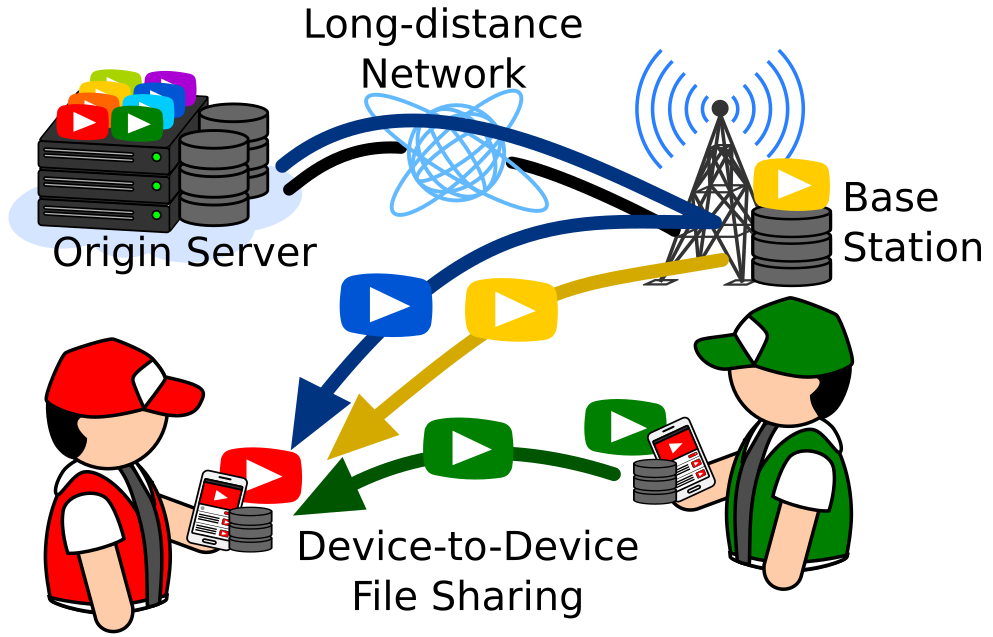
次世代モバイルネットワークの端末間通信の活用
第5世代の携帯電話ネットワークでは,携帯電話同士が基地局を介さず直接通信可能になります.また,基地局にはストレージが設置され,携帯電話端末のストレージ容量も増大すると考えられます.そこで,我々は携帯電話のストレージをキャッシュとして活用し,端末間の直接通信でファイルを共有することで,インターネット通信量の削減に取り組んでいます.
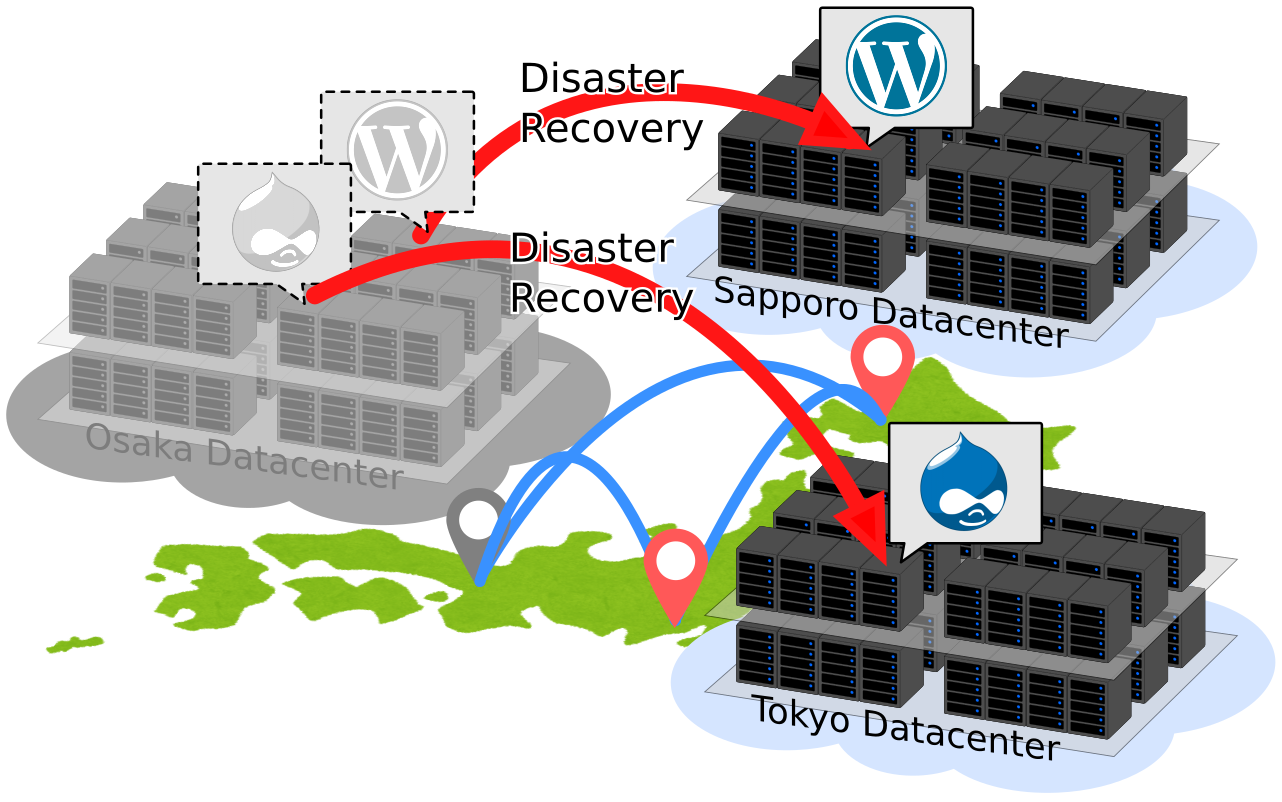
災害に強いクラウド基盤技術の開発
様々なサービスがクラウド上で提供されるようになった現在では,地震や津波などの大規模災害を受けてデータセンタ単位でサービスが停止するリスクが拡大しています.クラウドサービスは一般に複数の仮想マシンを組み合わせて構成が複雑化しているため,サービスの復旧には手動での作業が必要です.その結果,サービスの停止時間が伸びて多数の利用者に不利益が生じてしまいます.そこで,我々はクラウドサービスの停止時に,災害の影響を受けない遠隔地へのサービス再構築を自動化し,低コストで災害に強いクラウド基盤の実現に取り組んでいます.
アクセラレータ向け分散処理ソフトウェアライブラリ
FPGA向け分散処理ライブラリ “TAMAMO”
マルチFPGAボードを制御し、通信と計算を効率に行えるプログラミングフレームワークTAMAMO。このTAMAMOを使って光ネットワークやSATA、DRAM、DMAといった通信を兼ね備えたFPGAを活用できます。単体のFPGAボードの処理をノード分散させ、マルチFPGAノード処理を実現できます。
①ノード間を低レイテンシで制御
②巨大なデータをホストPCのメモリやプロセッサを経由せずにノード間を光ネットワークで通信
③光ネットワークや、DMAのインターコネクトの通信の際に並列FPGA処理の実行。
TAMAMOではこの3つの機能を、高性能FPGAクラスタで実現します。
このTAMAMOは githubで、オープンソースでの開発も行っています(※現在はAPX-7142ボードのみに対応)。2016に発表した研究会で受賞[nkawahara,CPSY-CEATEC’16]

GPU向け分散処理ライブラリ “FLAT”
マルチノードGPUを効率よく利用可能なプログラミングフレームワーク の取り組み。マルチノードGPUを使用するプログラムは、GPU上の処理を記述するコードとデータ通信処理を行うCPUのコードに分かれます。分かれたコードは、プログラマにとって見通しが悪く、また、機械的な最適化や形式検証を難しくしてしまいます。そこで、GPU同士のデータ授受を見通しよく記述できるようにするために、GPUコード中にMPIを埋め込み可能なプログラミングフレームワーク”FLAT”の研究を行いました。2013年に論文誌採録[島+,ACS’13]
ルーティング
ルーティンググループでは,ネットワークトポロジやフロー制御,ルーティングアルゴリズム,ルータマイクロアーキテクチャを中心にNoCの性能を向上させる手法について研究をおこないます.
詳細はこちら.
予測ルーティング
大規模クラスタ等の大規模ネットワークでの高速・効率的なルーティング手法を研究します. 具体的には,ネットワークの輻輳を予測したり,複数経路を比較検討することで,パケットを 安全かつ高速に配送可能なアルゴリズムを構築・実装します.
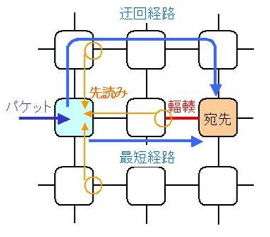
また,近年のSystem on Chip (SoC)の大規模化を受けて,光ネットワークによるオンチップ ネットワークを想定し,そこでの高速かつ効果的なルーティング手法についても研究しています. SoCにおける光ルーティングでは,高速・低レイテンシといった従来の指標に加えて,低消費電力 であることも重要視されます.
ルーティンググループは,国立情報学研究所および慶應義塾大学と共同研究を行なっています.
入試情報
吉永研究室は,大学組織の改組に伴い,独立研究科である大学院 情報システム学研究科(IS研究科)から.大学院 情報理工学研究科へと移籍しました.
移籍に伴い,従来の大学院入試に加えて,学部生の皆様の配属希望も受け入れています.電気通信大学の学内・学外を問わず,コンピュータシステムに興味がある方,研究に打ち込んでみたい方の応募をお待ちしています.
入試に関する情報は研究科の入試情報ページでご確認下さい.
